Practical LLM Tests
Visual PDF Parsing
Google AI Studio wins this, hands down, as of January 2025 - it’s the only site that actually does image recognition on your PDF and feeds the whole thing into context, without RAG. They do use your data for improving their models though, so keep that in mind.
An alternate way to do things is to use a PDF OCR text extractor tool on your PDF first, then paste the text into an LLM. Note that this will not do image recognition though, so make sure relevant images/slides have enough text describing them.
The point is to see how good an LLM is at understanding (and later summarizing / answering questions from) a PDF with both text and visual content. Say, lecture notes or slides.
Different LLM websites / tools parse PDFs differently. Some use OCR, some only extract the text portions. Some use RAG, some give the LLM all of the text. Some may even split the PDF into images for the LLM to parse. Depending on the method used, the quality of PDF understanding can vary, especially if there are diagrams or hand drawings in it.
Based on my testing, services either extract only the text portions of a PDF, or they do OCR on the image contents and include the extracted text from those. No production service seems to do any image understanding unless you explicitly feed the PDF in as multiple images, which is impractical and kinda sad. I guess it makes sense though, most PDFs are text heavy.
Test Methodology
Here is the OneNote page, which I exported as a PDF:

Findings
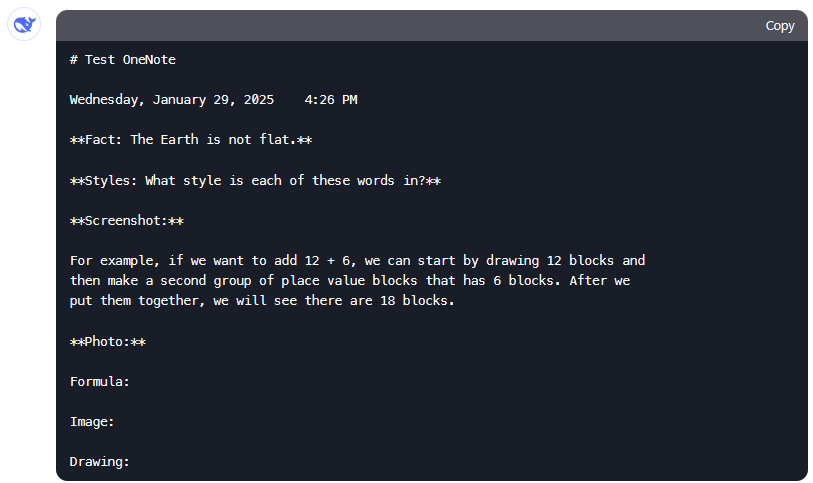
Surprisingly, Google AI Studio uses OCR and some basic image recognition on the PDF! It even recognizes the marshmallow picture and the triangle drawing. In addition, they allow for a huge context window, so large PDFs will work too if you’re willing to wait a bit for it to generate outputs (due to no RAG). Impressive! Note that it has to be the AI Studio, Gemini’s main website doesn’t allow PDF uploads. Gemini Flash 2.0 Experimental’s output:
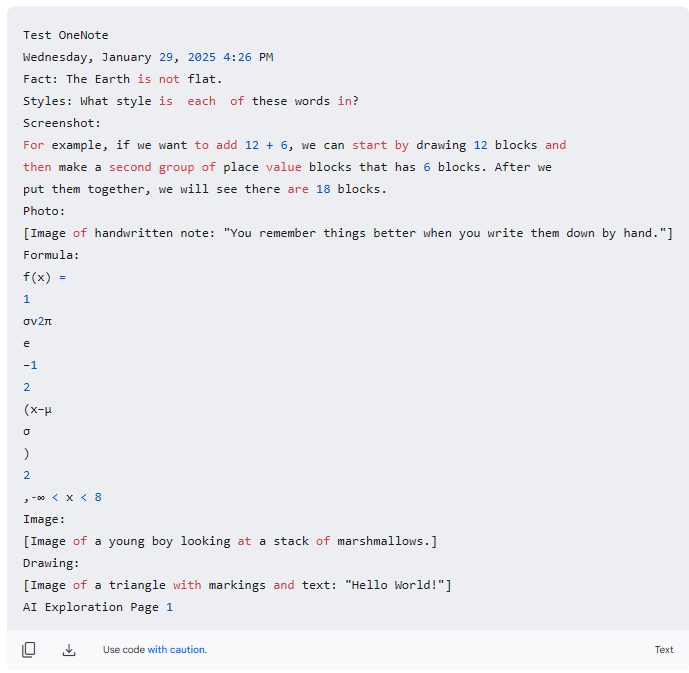
OpenAI/ChatGPT, Poe, and LM Studio all use just the actual text. For the services that just use the text in the PDF (RAG or not), they output something like this:
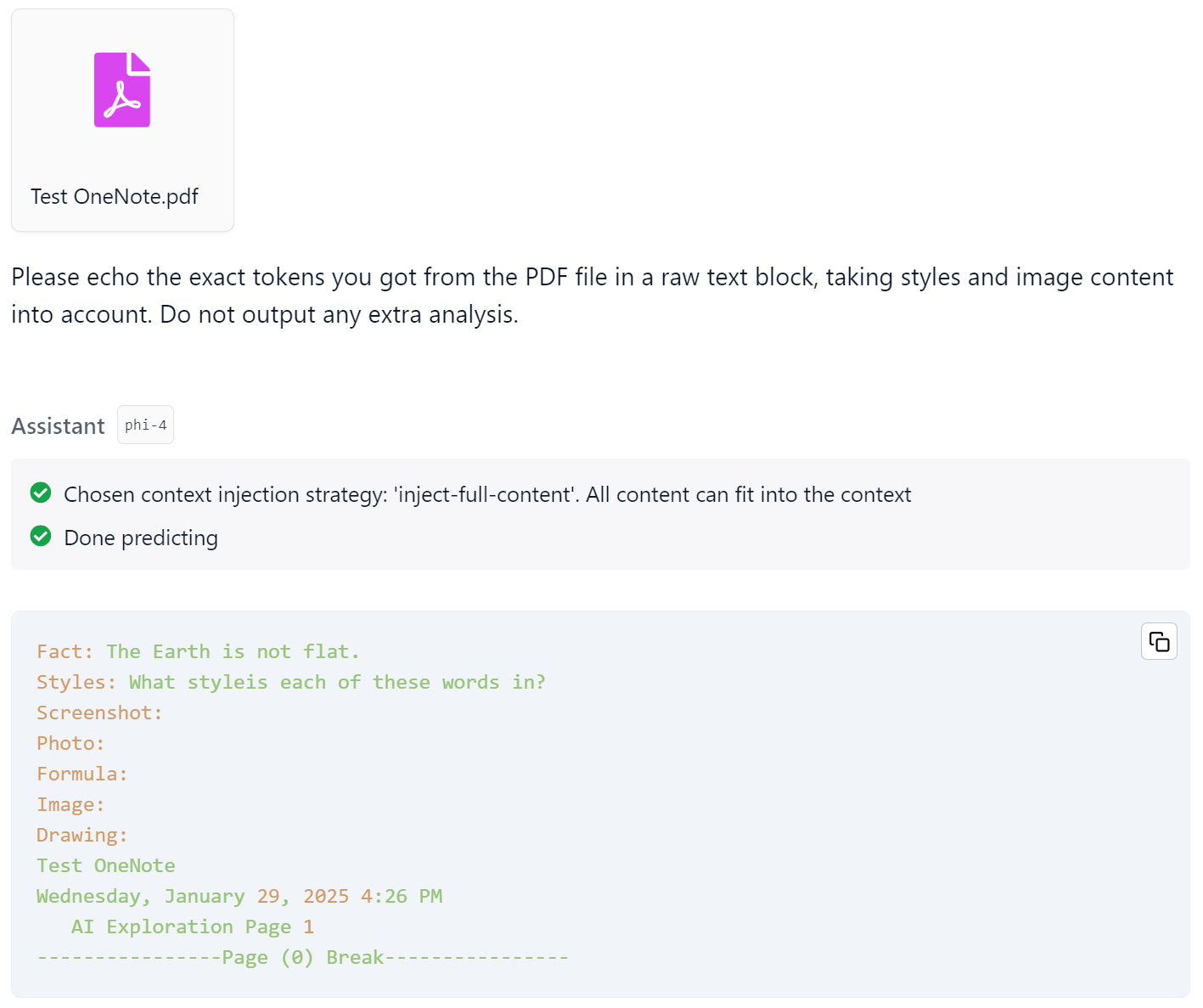
DeepSeek does a little better, parsing the computer font text, but missing the rest. DeepSeek’s output:
Online PDF summarizer sites like smallpdf.com didn’t do any OCR or image recognition, presumably because they just send the file to the above LLMs. Adobe’s AI Assistant also refused to parse my test PDF because it contained “too little text or too much text in images”.
Last updated: 29 January 2025